
The Evernote API is notable because it is not based on REST. The defense of that decision leaves me unimpressed.
When the world is going to REST, fully open and usable APIs, why would Evernote go the other way? They ought to have a good reason. Evernote’s VP of Platform Strategy Seth Hitchings has something to say about it. According to the article on ProgrammableWeb,…
Hitchings concedes that compared to the RESTful APIs, developers have to endure a bit of a learning curve to make use of the SDKs’ core functionality; to create, read, update, search, and delete Evernote content. But then again, according to Hitchings, Evernote is a special
needs case …
OK, so it’s more work for the consuming developers. It’s also more work for the company, because they have to support all the various “SDKs”, as they call them. [Evernote delivers libraries for various platforms including iOS, Android, C#, PHP, JavaScript, and more. They call these things “SDKs”, but they’re really not SDKs. An SDK is a Kit, that includes a libraries, documentation, example code, tools, and other stuff. When Evernote uses the word “SDK” they mean “library.”] So… why? Why do it if everyone has to do more work?
Seeking the least compromise to data-transfer performance, Evernote needed a solution that could shuffle large quantities of data with minimal overhead. Despite its superior efficiency over XML, REST still wasn’t good enough.
Whoa. REST has “superior efficiency over XML”? That’s just nonsense. REST is not a data format. REST is an architectural approach. REST does not mean “not XML”. If you want to transfer XML data using the REST approach, go ahead. That’s why Roy Fielding, Tim Berners-Lee, and Henrik F. Nielsen invented the Content-Type header. That’s what MIME types are for. You can transfer XML, or binary, or any sort of data with REST.
The implicit and incorrect assumption is that REST implies JSON, or that REST implies not binary. That’s false. There is no need to avoid REST in order to attain reasonable data transfer performance.
According to the article, that faulty reasoning is why Evernote selected Apache Thrift. Furthermore, as a benefit!! Thrift has tools to generate libraries for many platforms:
Thrift’s code-generating ability to write-once-and-deploy-to-many is also the reason Evernote is able to offer SDKs for so many platforms.
Yippee! But guess what! If you used REST, you wouldn’t need to generate all those libraries. And you’d have even broader platform support.
Just for fun, let’s have a look at the API that is being generated via Thrift. The Evernote API Reference looks like this:
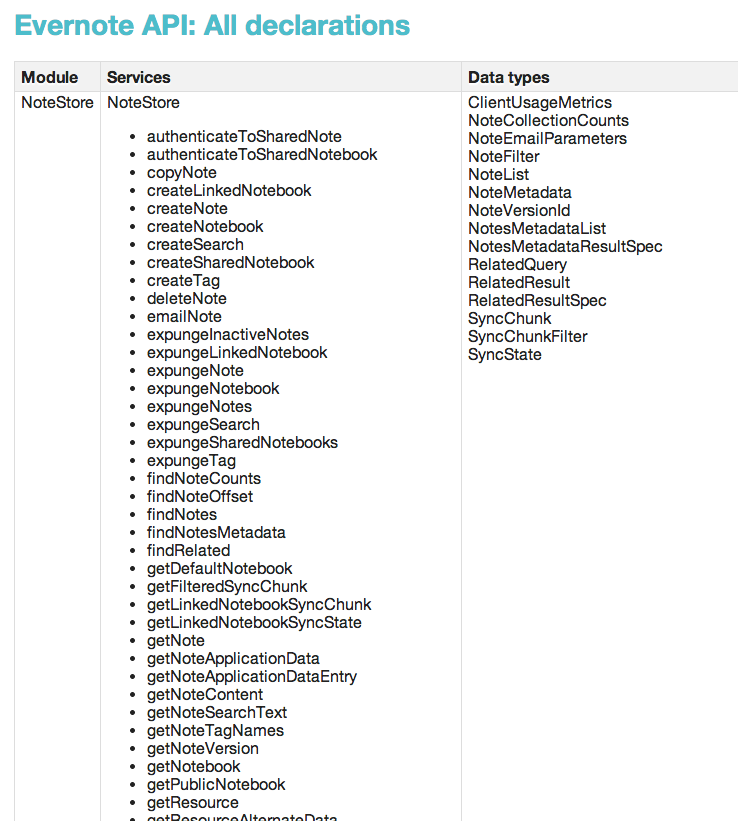
OMG, the horror. Look at all that stuff. The reason people like REST is that they can figure out the data model just by perusing the URLs. It’s obviously not possible to do so in this case.
Evernote’s is not a modern API. It is a mass of complexity.
Not impressed.



