Just read about SpaceMonkey moving from Python to Go.
This is why Google invented the language.
Smart move.
Just read about SpaceMonkey moving from Python to Go.
This is why Google invented the language.
Smart move.
I use emacs, have done so for a long time. Also a longtime fan of C#.
I wrote csharp-mode for emacs, to sort of cross the streams on those two interests.
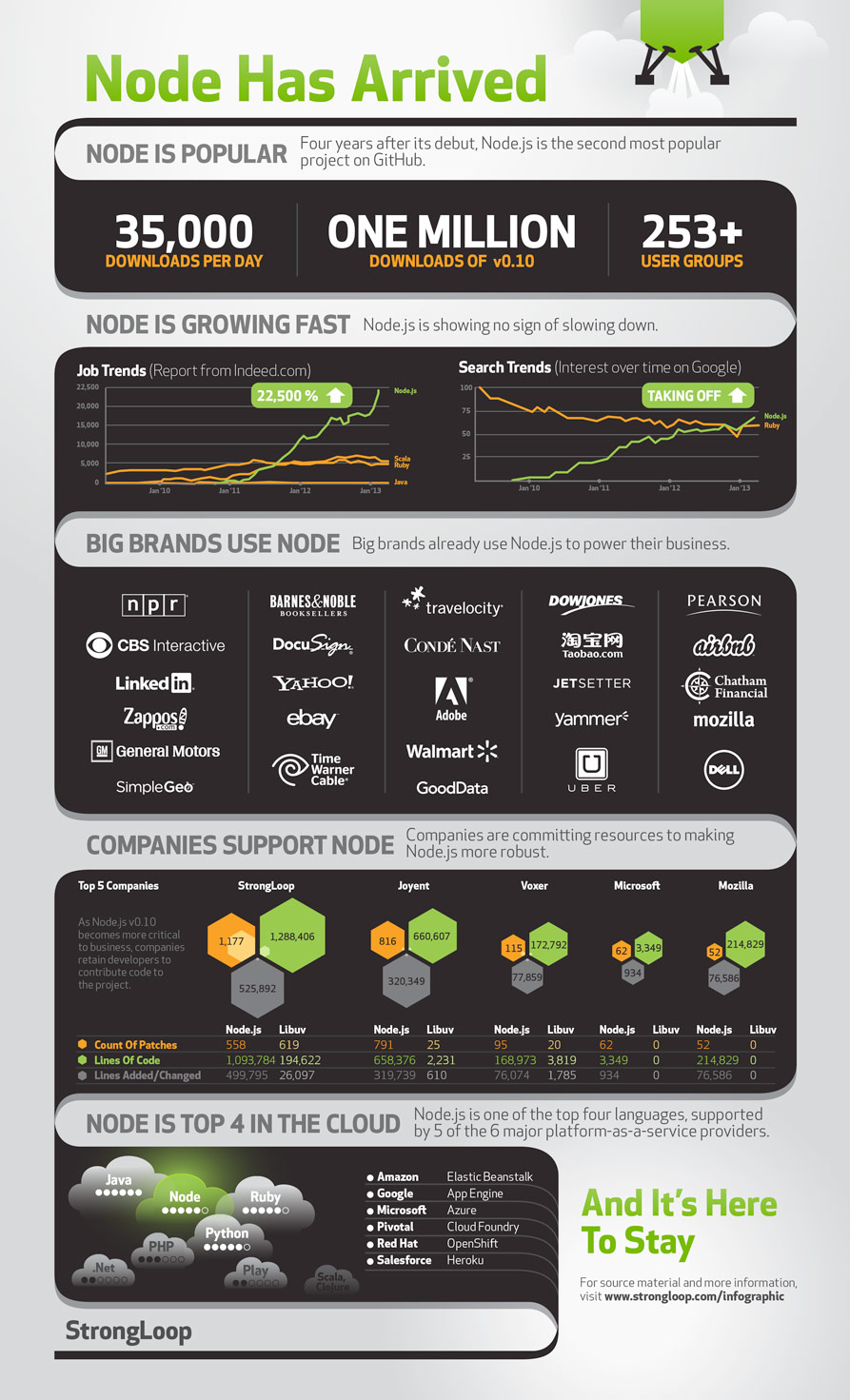
I recently found Flycheck – which is a turn-of-the-crank on the fantastic idea that was flymake. If you don’t know flymake, it is a tool that runs a syntax check on your file, after every change. For C#, it will compile the file. For JavaScript, it runs JSHint. For CSS, it runs CSS lint. And so on for python, PHP, Java and whatever else. Flymake is part of emacs.
Flymake is a great idea, but it has some flaws. For one thing, it runs too aggressively, even on buffers you cannot see. If you have lots of buffers open, it can kill your CPU. There are a couple other warts too. Over the years, people have learned to live with them.
Flycheck is the same idea, but with improvements.
I love open source innovation and community-driven advances!
Supposedly, with flycheck it is also easier to add in new “checkers” for various syntaxi. I don’t know if that’s true. I just built a C# checker for flycheck, and I had previously built checkers for C# (and for numerous other languages and tools) for flymake. It wasn’t so difficult in either case.
Anyway, here’s what you need to get flycheck to work with C# in emacs:
Add this to your init.el or .emacs or whatever:
And here’s how you use it:
Note the comment near the top of the file. This tells flycheck what to use for the checker command. You can specify anything there, including csc.exe on Windows.
I am now using a Mac as my main laptop, and yes, you can do C# on Mac with Mono. And this flycheck thing works there, too, natcherully.
Flycheck “encourages” contributions, but the requirements are a bit too onerous for me. This potential enhancement won’t be accepted without unit tests and a bunch of other stuff. I’m not bothering with all that. So I’m just publishing this, thinking people might find it to be useful. For now, anyone can use this; it just works.
ps: you will need to have, on your path, the directory that contains the gmcs tool and the pkg-config tool, if you use mono. On MacOS this is /Library/Frameworks/Mono.framework/Versions/Current/bin . You can do this in emacs, this way:

The Evernote API is notable because it is not based on REST. The defense of that decision leaves me unimpressed.
When the world is going to REST, fully open and usable APIs, why would Evernote go the other way? They ought to have a good reason. Evernote’s VP of Platform Strategy Seth Hitchings has something to say about it. According to the article on ProgrammableWeb,…
Hitchings concedes that compared to the RESTful APIs, developers have to endure a bit of a learning curve to make use of the SDKs’ core functionality; to create, read, update, search, and delete Evernote content. But then again, according to Hitchings, Evernote is a special
needs case …
OK, so it’s more work for the consuming developers. It’s also more work for the company, because they have to support all the various “SDKs”, as they call them. [Evernote delivers libraries for various platforms including iOS, Android, C#, PHP, JavaScript, and more. They call these things “SDKs”, but they’re really not SDKs. An SDK is a Kit, that includes a libraries, documentation, example code, tools, and other stuff. When Evernote uses the word “SDK” they mean “library.”] So… why? Why do it if everyone has to do more work?
Seeking the least compromise to data-transfer performance, Evernote needed a solution that could shuffle large quantities of data with minimal overhead. Despite its superior efficiency over XML, REST still wasn’t good enough.
Whoa. REST has “superior efficiency over XML”? That’s just nonsense. REST is not a data format. REST is an architectural approach. REST does not mean “not XML”. If you want to transfer XML data using the REST approach, go ahead. That’s why Roy Fielding, Tim Berners-Lee, and Henrik F. Nielsen invented the Content-Type header. That’s what MIME types are for. You can transfer XML, or binary, or any sort of data with REST.
The implicit and incorrect assumption is that REST implies JSON, or that REST implies not binary. That’s false. There is no need to avoid REST in order to attain reasonable data transfer performance.
According to the article, that faulty reasoning is why Evernote selected Apache Thrift. Furthermore, as a benefit!! Thrift has tools to generate libraries for many platforms:
Thrift’s code-generating ability to write-once-and-deploy-to-many is also the reason Evernote is able to offer SDKs for so many platforms.
Yippee! But guess what! If you used REST, you wouldn’t need to generate all those libraries. And you’d have even broader platform support.
Just for fun, let’s have a look at the API that is being generated via Thrift. The Evernote API Reference looks like this:
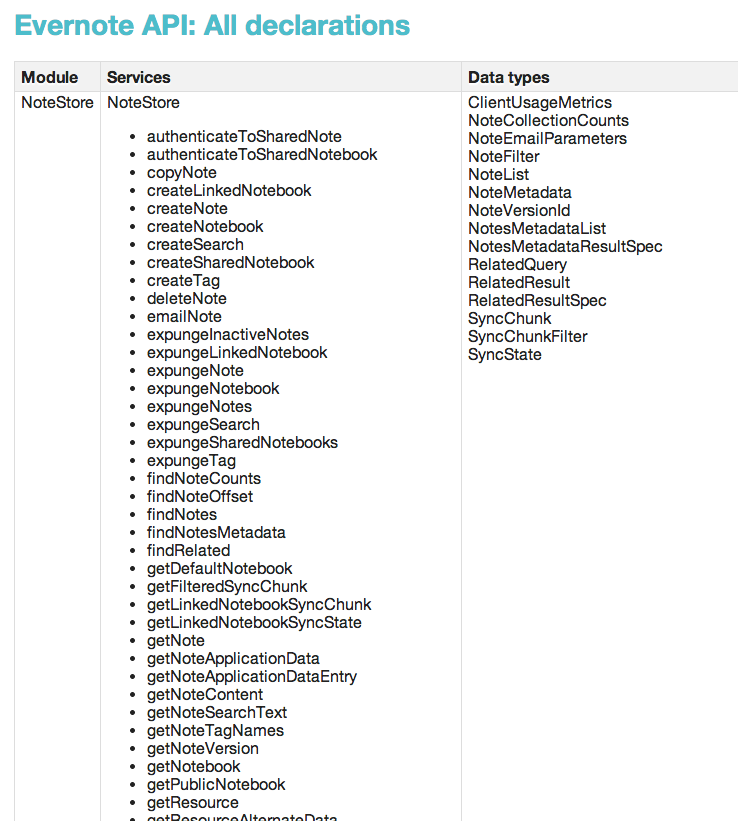
OMG, the horror. Look at all that stuff. The reason people like REST is that they can figure out the data model just by perusing the URLs. It’s obviously not possible to do so in this case.
Evernote’s is not a modern API. It is a mass of complexity.
Not impressed.

Remember a while back when I wrote that Node.js is popular and getting moreso?
Well, today I came across a blog that explains why.
In the very clearest terms.
Bookmark this: How Node.js is Going to Replace JavaScript

Pop.co explains why they went to an API-first development model.
This is going to be a continuing trend. More and more places are already doing this, even if they’re not blogging or talking about it. With the continued growth of mobile devices, to become co-equal with a website, if not the predominant way that people interact with companies, there is an imperative to go to APIs first.
Why?
Everyone is going to be doing this.
I don’t agree with everything in that POP.co post. For example, POP lists “Scalability” as a reason for going to APIs. I don’t see it. Their theory is that Separation of concerns leads to scalability, meaning they can have web servers and API servers and scale them independently. But Microsoft refuted this as a requirement for high performance long ago. ASPNET proved that you can build a stateless layer of web/app servers, backed by a fast datastore layer, that screams. There’s no real performance benefit to separating the HTML server from the “API Server”.
On the other hand, the other reasons that POP.co offers for going to APIs first, make a ton of sense to me.
A while back I commented on a rant by someone who said that NodeJS is stupid and if you use it, so are you.
I didn’t agree.
But, NodeJS documentation is stupid. Look, for example, at the doc for the http.request() object and it’s syntactic sugar cousin, http.get(). Let’s suppose you want to do an http get from within a node program. So you look at the doc for http.get, which says: This is like http.request(), except it sets the method to GET and calls req.end() automatically.
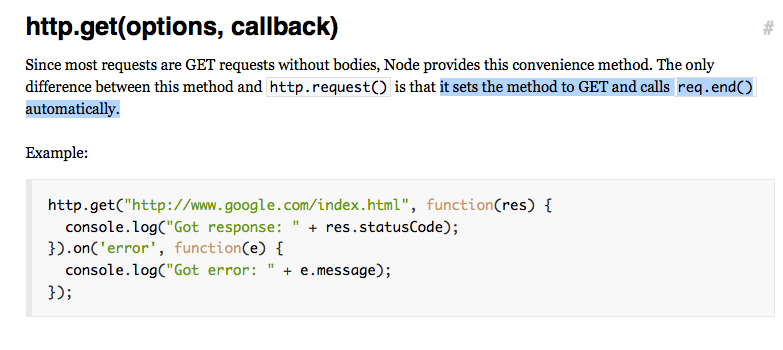
I wonder what that callback parameter is? http.get() accepts a callback parameter. Obviously it’s a function, but WHEN Does it get called? The doc doesn’t say.
Hmm, not very much to go on! So now I have to read the entire entry on the http.request() function. The http.get() sugar doesn’t really offer much benefit if I have to read the doc for the lower-level method, now, does it? But guess what! The doc entry for http.request() ALSO does not define the semantics of the callback parameter. It’s just a callback.
I guess if I have to ask, then I don’t need to know.

Apigee is looking for a few good SEs.
An SE is a Sales Engineer. At Apigee, this is a member of the sales team who’s very technically adept, loves technology, and loves talking to other technologists about how to apply cool technology to solve hard problems.
This person needs to have a good developer background in server-side apps programming, with good C++, Java or C# skills, and probably one or more of Python, Ruby, PHP and NodeJS. Of course should know APIs, REST, SOAP very well, and should be handy with JSON, XML, and the various tools around those. Ought to know who Roy Fielding is, why jQuery is named jQuery, should know what RFC 2616 is, must love clouds, big data. Experience with AWS, Azure, RackSpace, VMware or IBM Smartcloud is a big plus. Beyond all that, the person’s got to love dealing with smart people with different perspectives.
If you know someone who fits this bill, lives near one of the NFL cities in the USA (you know, New York, Boston, Atlanta, Dallas, Houston, Chicago, Denver, San Fran, Los Angeles, etc), and wants to work for an ambitious late stage startup, send em my way: @dpchiesa on twitter.
Bruce Schneier is often right.
And he’s right again. Edward Snowden is doing the country a great service, by exposing the NSA data collection program.

I use github gists, and sometimes I want to embed a gist into a blog post. Using the script block github provides gives me poor results. There are several problems:
Good effort by github, but not usable for me out of the box. I resorted to using the github api directly, and embedding the retrieved content using jQuery. This is also not optimal because the styling and line numbering is missing. See my recent post on ASP Classic for a visual example. Also it takes longer for me to write the markup that does this.
With the help of this blog post, which I found from this stackoverflow question, I was able to style it properly without doing too much css archaeology. Reasonable result: