Having access to a quick way to get dictionary lookups of English words while using the computer has always been useful to me. I don’t like to pay the “garish dancing images” ad tax that comes with using commercial dictionary sites like merriam-webster.com; or worse, the page-load-takes-10-seconds tax. I respect Merriam-Webster and appreciate all they’ve done for the English language over the years, but that doesn’t mean I am willing to put up with visual torture today. No, in fact I do not want to download a free e-book, and I do not want to sign up for online courses at Capella University. I just want a definition.
Where’s the API?
I’m a closet hacker, so I figured there had to be an API out there that allowed me to build something that would do dictionary lookups from … whatever application I was currently using.
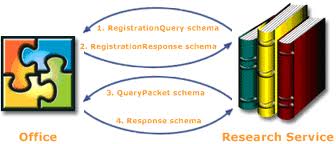
And looking back, this is an ongoing obsession of mine, apparently. In the job with Microsoft about 10 years ago, I spent a good deal of my time writing documents using Microsoft Word. I had the same itch then, and for whatever reason I was not satisfied with the built-in dictionary. So I built an Office Research Plugin, using the Office Research Services SDK (bet you never heard of that), that would screen-scrape the Merriam-Webster website and allow MS-Word to display definitions in a “smart pane”. The guts of how it worked was ugly; it was brittle in that every time M-W used a different layout, the service would break. But it worked, and it displayed nicely in Word and other MS-Office programs.
The nice thing was that Microsoft published an interface that any research service could comply to, that would allow the service to “plug in” to the Office UI. The idea behind Office Research Services was similar to the idea behind Java Portlets, or Sharepoint WebParts, or even Vista Gadgets, though it was realized differently than any of those. In fact the Office Research Services model was very weird, in that it was a SOAP service, yet the payload was an encoded XML string. It wasn’t even xsd:any. The Office team failed on the data model there.
It was also somewhat novel in that the client, in this case the MS-Office program, specified the interface over which the client and service would interact. Typically the service is the anchor point of development, and the developer of the service therefore has the prerogative to specify the service interface. For SOAP this specification was provided formally in WSDL, but these days the way to connect to a REST service can be specified in WADL or Plain-old-Documentation. The Office Research Service was different in that the client specified the interface that research services needed to comply to. To me, this made perfect sense: rather than one service and many types of clients connecting to it, the Office Research Service model called for one client (Office) connecting to myriad different research services. It was logically sensible that the client got to specify the interface. But I had some discussions with people who just could not accept that. I also posted a technical description showing how to build a service that complied with the contract specified by Office.
The basic model worked well enough, once the surprise of the-client-wears-the-pants-around-here wore off. But the encoded XML string was a sort of an ugly part of the design. Also, like the Portlet model, it mixed the idea of a service with UI; the service would actually return UI formatting instructions. This made sense for the specific case of an Office service, but it was wrong in the general sense. Also, there was no directory of services, no way to discover services, to play with them or try them out. Registration was done by the service itself. There are some lessons here in “How not to do APIs”.
Fast Forward 9 Years
We’ve come a long way. Or have we? Getting back to the dictionary service, WordNik has a nice dictionary API, and it’s free! for reasonable loads, or until the good people at WordNik change their minds, I guess.
It seemed that it would be easy enough to use. The API is clear; they provide a developer portal with examples of how to use it, as well as a working try-it-out console where you can specify the URLs to tickle and see the return messages. All very good for development.
But… there are some glaring problems. The WordNik service requires registration, at which point the developer receives an API key. That in itself is standard practice. But, confoundingly, I could not find a single document describing how to use this API key in a request, nor a single programming example showing how to use it. I couldn’t even find a statement explicitly stating that authentication was required. While the use of an API key is pretty standard, the way to pass the API key is not. Google does it one way, other services do it another. The simplest way to document the authentication model is to provide a short paragraph and show a few examples. Wordnik didn’t do this. Doesn’t do this. I learned how to use the WordNik service by googling and finding hints from 2009 on someone else’s site. That should not be acceptable for any organization offering a programmable service.
In the end I built the thing – it’s an emacs plugin if you must know, and it uses url.el and json.el to connect to Wordnik and display the definition of the word at point. But it took much longer, and involved much more frustration than was necessary. This is not something that API providers want to repeat.

The benefits of interconnecting disparate piece-parts have long been tantalizingly obvious. You could point to v0.9 of the SOAP spec in 1999 as a key point in that particular history, but IBM made a good business of selling integration middleware (MQ they called it) for at least a decade before that. Even so, only in the past few years have we seen the state of the art develop to enable this on an internet scale. We have cheap, easy-to-use server frameworks; elastic hosting infrastructure; XML and JSON data formats; agreement on pricing models; an explosion in mobile clients.
Technologies and business needs are aligning, and this opens up new opportunities for integration. To take advantage of these opportunities, companies need the right tools, architectural guidance, and solid add-on building blocks.

I’ve recently joined Apigee, the API Company, to help companies exploit those opportunities. I’ll say more about my job in the future. Right now, I am very excited to be in this place.