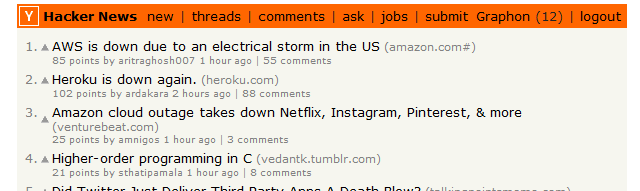
How to Discourage Adoption of Public Cloud by Enterprises
2012-June-29
I previously wrote about the black hole of submitting job applications electronically.
The Wall Street Journal explains how that phenomenon occurs.
To cut through the clutter, many large and midsize companies have turned to [automatic] applicant-tracking systems to search résumés for the right skills and experience. The systems, which can cost from $5,000 to millions of dollars, are efficient, but not foolproof.

Efficient, but not foolproof? Is that a way of saying “Fast, but wrong”?
If a system very efficiently does the wrong thing, well it seems like not a very good system.
WSJ goes on to say,
At many large companies the tracking systems screen out about half of all résumés, says John Sullivan, a management professor at San Francisco State University.
All well and good. I understand that it’s expensive to even evaluate people for a job, and if a company gets thousands of resumes they need some way of managing their way through the noise.
On the other hand it sure seems like a bunch of good candidates are being completely ignored. There are a lot of false negatives.
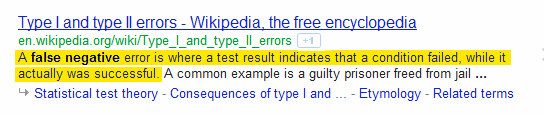
It sure seems to me that the system isn’t working, the way it is now. Companies can rely on recruiters, but that can be very expensive. They can rely on online job boards, but that’s a frustrating recipe for lots of noise.
Thankfully though, not all companies rely solely on online job submission forms, in order to source candidates.
I am bullish on Hadoop and other NoSQL technologies. Long-term I believe they will be instrumental in providing quantum leaps in efficiency for existing businesses. But even more, I believe that mainstream BigData will open up brand new opportunities that were simply unavailable before. Right now we focus on applying BigData to user activity and clickstream analysis. why? Because that’s where the data is. But that condition will not persist. There will be oceans of structured and semi-structured data to analyze. The chicken-and-egg situation with the tools and the data will evolve, and brand new application scenarios will open up.
So I’m Bullish.
On the other hand I don’t think Hadoop is ready for prime time today. Why? Let me count the reasons:

Curt Monash, writing on The DBMS2 blog, addressed the enterprise readiness of Hadoop recently.
tl/dr:
Hadoop is proven indeed, whether in technology, vendor support, or user success. But some particularly conservative enterprises may for a while disagree.
But is Mr Monash really of one mind on the topic? especially considering that he began the piece with this:
Cloudera, Hortonworks, and MapR all claim, in effect, “Our version of Hadoop is enterprise-ready, unlike those other guys’.” I’m dubious.
So the answer to “is it enterprise ready?” seems to be, clearly, “Well, yes and no.”
With my understanding of the state of the tools and technology, and the disposition of enterprises, unlike Mr Monash I believe most enterprises don’t have the capacity or tolerance to adopt Hadoop currently. It seems to me that immaturity still represents an obstacle to new Hadoop deployments.
The Hadoop vendor companies and the Hadoop community at large are addressing that. They’re building out features and Hadoop 2.0 will bring a jump in reliability, but there is still significant work ahead before the technology becomes acceptable to the mainstream.
Be excellent at anything! Tony Schwartz of HBR tells us how to do it.
My takeaways:

Rob Enderle demonstrates his fondness for dramatic headlines with his piece, The Death and Rebirth of Microsoft. A more conservative editor might headline the same piece, “Microsoft Steadily Shifts its Strategy.”
Last week, Microsoft (Nasdaq: MSFT) effectively ended the model that created it. This shouldn’t have been a surprise, as the model hasn’t been working well for years and, as a result, Microsoft has been getting its butt kicked all over the market by Apple (Nasdaq: AAPL).
Well Microsoft apparently has had enough, and it decided to make a fundamental change and go into hardware.
Aside from the hyperbole, Mr Enderle’s core insight is correct: Microsoft is breaking free of the constraints of its original, tried-and-true model, the basis of the company for years. Under than plan, Microsoft provided the software, someone else provided the hardware. Surface is different: it’s Microsoft hardware, and it signifies a major step toward the company’s ability to deliver a more integrated Microsoft experience on thin and mobile devices. This aspect of the Surface announcement was widely analyzed.
This is what you may not have noticed: Azure is the analogous step on servers. With Azure, Microsoft can deliver IT infrastructure to mid-market and enterprise companies, without the dependence on OEM partners, nor on the ecosystem that surrounds the phenomenon of OEM hardware installation – the networking and cabling companies, the storage vendors, the management software vendors and so on.
Just as Surface means Microsoft is no longer relying upon HP or Acer to manufacture and market cool personal hardware, and the rumored Microsoft handset would mean that Microsoft won’t be beholden to Nokia and HTC, Azure means Microsoft will not need to rely on Dell or HP or IBM to produce and install server hardware.
That is a big change for a company that was built on a strategy of partnering with hardware vendors. But times are different now. Microsoft is no longer purely software. In fact it is outgrowing its name, just as “International Business Machines” as a name has lost its meaning for a company that brings in 57% of its revenue through services. But while this is a big step, it’s not an a black-and-white thing. Microsoft maintains relationships with OEMs, for PCs, laptops, mobile devices and servers, and that will continue. Surface and Azure are just one step away from purity of that model.
Microsoft’s Azure, and Amazon’s AWS too, presents the opportunity for companies to completely avoid huge chunks of capital cost associated to IT projects; companies can pay a reasonable monthly fee for service, rather than undertaking a big investment and contracting with 4 or 5 different vendors for installation. That’s a big change.
Very enticing for a startup, or a small SaaS company.
I was reading through some of the Microsoft chatter surrounding TechEd, the company’s massive annual technical conference.
One of the blog posts got my attention with this headline:
I wasn’t clear on just what that meant, so I clicked through, of course.
The biggest news there is about System Center, which is an IT Pro management tool. Apparently the latest offering has some new features that help sysadmins manage “private clouds”, which I suppose refers to on-premises pools of computers that are allocated out in some flexible manner. Sounds like useful stuff. The proof is in the pudding of course.
But the thing that caught my eye was one of the partner news items. A “cloud offering” from Dell.

OK, now I know what Dell thinks a cloud looks like. 🙂
A video of his one-hour presentation with slides + demo.
Originally Windows Azure was a Platform-as-a-Service offering; a cloud-hosted platform. This was a new platform, something like Windows Server, but not Windows Server. There was a new application model, a new set of constraints. With the recent announcement, Microsoft has committed to running arbitrary VMs. This is a big shift towards what people in the industry call Infrastructure-as-a-Service.
Russinovich said this with a straight face:
One of the things that we quickly realized as people started to use the [Azure] platform is that they had lots of existing apps and components that they wanted to bring onto the platform…
It sure seems to me that Russinovich has put some spin into that statement. It’s not the case that Microsoft “realized” customers would want VM hosting. Microsoft knew very well that customers, enterprises in particular, would feel confidence in a Microsoft OS hosting service, and would want to evaluate such an offering as a re-deployment target for existing systems.
This would obviously be disruptive, both to Microsoft partners (specifically hosting companies) and to Microsoft’s existing software licensing business. It’s not that Microsoft “realized” that people would want to host arbitrary VMs. They knew it all along, but delayed offering it to allow time for the partners and its own businesses to catch up.
Aside from that rotational verbiage, Russinovich gives a good overview of some of the new VM features, how they work and how to exploit them.
Today I had a bit of a puzzle. The gplus widget that I wrote for WordPress was rendering Google+ activity with a ragged left edge.

As geeks know, html by default collapses whitespace, so in order for the ragged edge to appear there, a “hard whitespace” must have crept in, somewhere along the line. For example, HTML has entites like that will do this. A quick look in the Chrome developer tool confirmed this.
I figured this was a simple fix:
$content = str_replace(" "," ", $content);
Simple, right?
But that didn’t work.
Hmmm…. Next I added in some obvious variations on that theme:
$content = str_replace(" "," ", $content);
$content = str_replace("\n"," ", $content);
$content = str_replace("\r"," ", $content);
That also did not work.
This data was simple json, coming from Google+, via their REST API. (But not directly. I built caching into the gplus widget so that it doesn’t hit the Google server every time it renders itself. It reads data from the cache file if it’s fresh, and only connects to Google+ if necessary). A call to json_decode() turns that json into a PHP object, and badda-boom. Right?
Turns out, no. The json had a unicode sequence 0xC2A0, which I guess is a non-breaking space if you speak Unicode. Not sure how that got into the datastream, I certainly did not put it in there myself, explicitly. And when WordPress rendered the widget, that sequence somehow, somewhere got translated into , but only after the gplus widget code was finished.
I needed to replace the unicode sequence with a regular whitespace. This did the trick.
$content = str_replace("\xc2\xa0"," ", $content);
PHP, JSON, HTTP, HTML – these are all minor miracle technologies. Sometimes when gluing them all together you don’t get the results you expect. In those cases I’m glad to have a set of tools at my disposal, so I can match impedances.
Microsoft is a Cloud-first company, asserts Jonathan Hassell.
Not sure that’s completely accurate, or helpful. He’s right that Microsoft is accentuating the cloud offerings, these days, and is really pushing to exploit what is a once-every-two decades kind of disruptive development in the industry.
On the other hand the lion’s share of Microsoft’s revenue still derives from on-premises software, in its “traditional strongholds.”