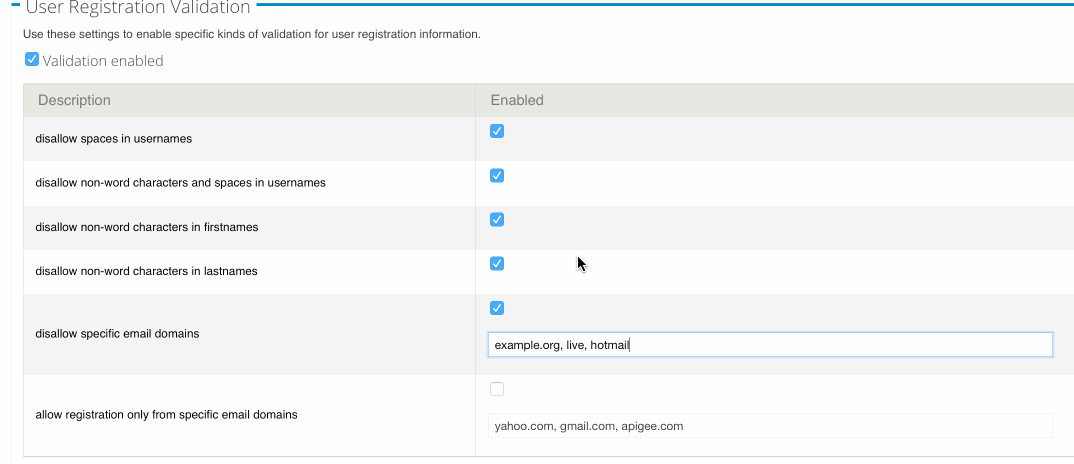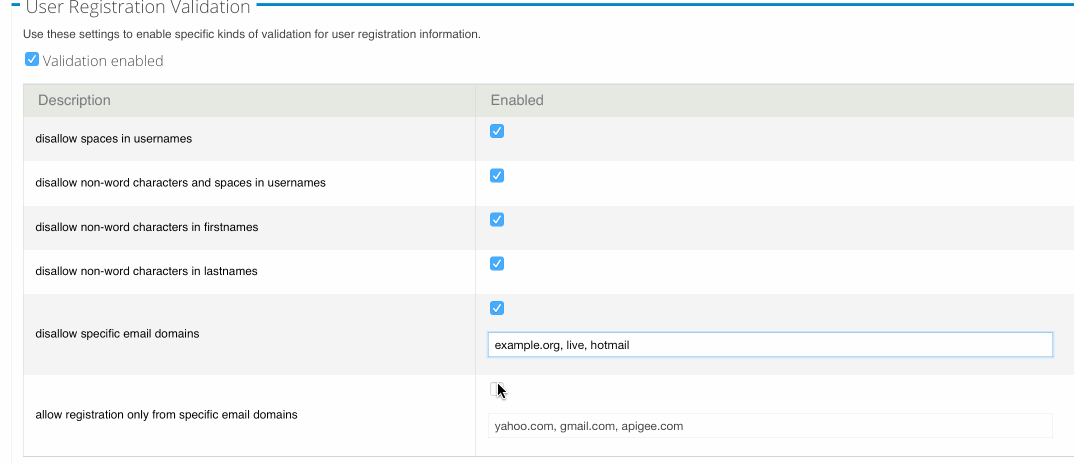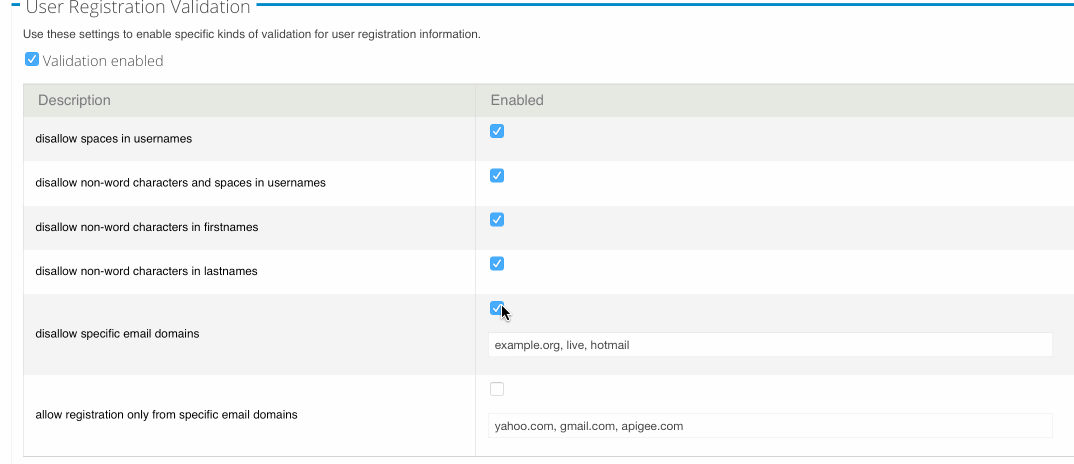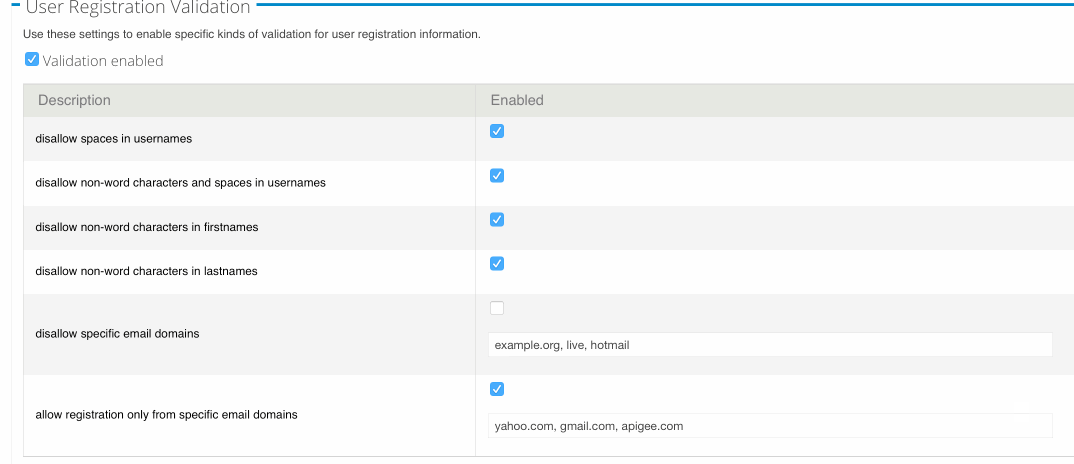
Yes, it’s that time of year when people think about RFC7523, which describes how to exchange JWT for opaque OAuth tokens.
Right?
If you’re like me, the waves of acronyms, jargon, and IETF RFCs (see what I did there?) seem to never end. OAuth, JWT, RFC 7523, JTI, claims, RS256, PBKDF2…? I feel your pain.
But there is some good news… here’s something that will help clarify the ideas and use cases around RFC7523. I wrote a quick article, and also created an Apigee Edge API Proxy, that implements this for you. It illustrates exactly how to exchange JWT for opaque OAuth tokens, and I even include some commentary int he readme explaining why you’d want to do it. (Spoiler alert: It’s faster to verify opaque OAuth tokens). All available on the Apigee community site.
The way I think about RFC7523 – it is an alternative to the client_credentials “grant type”, described in IETF RFC6749, which is the document that describes the OAuth v2.0 Framework.
OK, I hear you saying it: “back up, Dino… What is this client_credentials thing?” Yes, there is an underscore there. The client_credentials grant type is designed to allow a client app to identify itself to a token dispensary. The client says “here’s my ID, and here’s a secret that only I (the client app) should know.” And the token dispensary can then look at those two pieces of information, and if they are valid (the client_id is not expired or revoked), then the token dispensary can issue a token. It’s like username + password authentication for a person, but client_credentials is used for identifying a client app. This grant type mostly useful in server-to-server communications, when one service is being used by another service. BUT, some people use client_credentials grants in their mobile apps, so that the API service can trust that the mobile app is who it claims to be. (There are some problems with this; basically the client_secret needs to be embedded in the client code, therefore it is accessible to hackers, and therefore it is not truly “secret”. We can talk about mitigations for this in a future blog post.)
So that’s the client_credentials grant type. As I said, RFC7523 is an alternative to the client_credentials grant. Basically, instead of sending in a client_id and client_secret, under the RFC7523 flow (which has the helpful and easy-to-remember moniker of “JSON Web Token (JWT) Profile for OAuth 2.0 Client Authentication and Authorization Grants”, seriously) the client app self-signs a JWT which includes the client_id as the issuer. The app sends that to the token dispensary. The token dispensary verifies the signature, verifies that the client_id is valid, and then issues an opaque OAuth v2.0 token.
Now, there are some interesting implications to this model. Maybe these are obvious to some of you, but I will state them anyway:
- the token dispensary and the client app have to conform to the same JWT signing convention. JWT can be signed with shared-secret (HS256) or with public/private key (RS256). Either way is fine, but the two sides must agree.
- regardless of the signing convention, it must be possible for the token dispensary to verify the signature. If HS256 is the agreed convention, this means the token dispensary and the client app must share a secret. (This can be the client_secret! if it has sufficient entropy, or it can be a key obtained from PBKDF2) If RS256 is the signing convention, it means the two parties must have a shared trust relationship, where the token dispensary has access to the public key of the client app. Bottom line, there is a little bit more overhead for you, setting up an JWT-for-opaque-token exchange mechanism, if you use RS256: specifically you need to provision a new RSA public/private keypair for the client, and the client needs to make the public key available to the token dispensary.
- the client app needs some extra intelligence, specifically a library that allows it to create a signed JWT. There are myriad options available regardless of the app platform + language you use, so in practice, this won’t be an obstacle, but it does mean there will be new code you must include in your client.
Once you get past those implications and the extra set-up overhead, the model in RFC 7523 is really nice because it’s extensible. That’s because the request-for-token is encapsulated in a JWT, and the JWT itself is extensible. You, as an API designer, can stipulate any arbitrary (custom) claims that clients must include in the JWT, in order to compose a valid request-for-token. And you can include restrictions on the standard claims or custom claims. Some examples:
- a proof-of-work string, something like a HashCash string or similar. Including proof-of-work would be a discouragement for bots.
- As another example, you can stipulate that the JWT be short lived. Verification of the JWT might include a proviso that rejects tokens that have a lifetime beyond 180 seconds, for example.
- you could institute a one-use policy on such JWT.
- you could require a “scopes” claim and validate the strings contained in that claim against the issuer (==client_id)
BTW, the example API Proxy I shared on Github shows how to implement the lifetime and one-use-only controls. (As with everything I publish on github, pull requests are welcomed!) If the inbound JWT that comprises the request-for-opaque-token does not pass these checks, a 401 Unauthorized is sent back.
BTW #2, did you know that Google services like Stackdriver and cloud storage use JWT-for-opaque-token exchange in order to enable service-to-service integration? Google also institutes the lifetime and one-use-only controls. The lifetime of the JWT must be less than 300 seconds.
Say, that reminds me!, Speaking of Google, did I mention that Google has acquired Apigee? Yes, I work for Google now! Part of the Apigee team within Google. w00t! I’m pumped, psyched, charged up, amped, and very pleased about this development.
So far, minimal changes for me, except for me I got a Chromebook! And yes, I authored this post from that very same device.
As always, I’m interested to hear your feedback on this. Let me know in the comments section.
Finally, I would like to wish all of you a Merry RFC7523 Season; and I wish you many Happy short-lived OAuth Tokens in the new year.